理论上来讲,可以用Python爬虫从医院信息系统(HIS)中批量获取各种想要的数据,并进行数据处理和数据分析(这实际上是信息科应该干的事情)。这些数据可以是患者的病理Gleason评分、结石的大小、肿瘤的大小、某个抽血指标、主诉时长、手术时长、出血量等等。数据较少、廉价劳动力充足时,爬虫技术并不具有优势。
本文用一个从病理系统中批量获取患者Gleason评分的Python脚本,测试一下可行性。
脚本功能
根据Excel中的患者信息列表,从病理系统中查询Gleason评分,并填入Excel中。
需要用到的工具
这是一个Python 3 脚本,在如下环境调试完成。
- Microsoft Windows 7 32位:医院办公室最高级的系统,XP安装新版Anaconda和PyCharm时有问题。
- Anaconda3-5.0.1-Windows-x86.exe:墙内用户可从清华大学开源软件镜像站下载
- PyCharm-community-2016.3.3.exe:2017年的社区版安装包提示错误,只能安装旧一版。若在自己电脑上,可用专业版,edu邮箱用户福利。
- xlutils模块: Anaconda已内置其他所需模板,只需要离线安装这一个。
- Google Chrome: 医院信息科在落后的Win7上安装了Chrome,真神奇
- 健迅HIS系统:始于1835的老系统
- 朗珈病理查询系统:一个网页版的查询系统
- Microsoft Office 2010: 不能是WPS或Libre Office
使用流程
一、从电子病历系统中导出患者信息列表
这是健讯电子病历系统一个难得的好功能。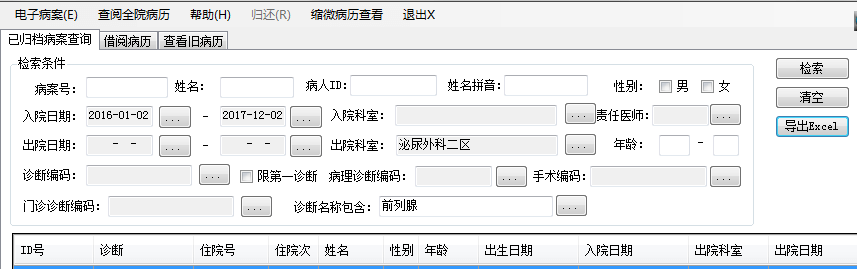
然而导出的Excel文件后缀是错误的,文件实际为xlsx格式,文件名却是xls。导出之后用M$ Excel 2010(或更高版本)打开,点击文件→转换,转换成xlsx文件

然后再把它保存为xls格式,因为我Python脚本中用的是xls的读写模块。
打开这个文件可以看到,只有一个名为“ds”的sheet,共有14列,第2列是住院号,第1行为标题

二、配置python脚本
把上述xls文件与Hospital_information_system_crawler_for_Gleason_Score.py脚本放同一个文件夹,用PyCharm 打开py脚本,把xls文件名填入到脚本中
1 | xls_file = 'Prostate_Cancer_Jan_Nov.xls' |
三、自动获取Gleason 评分
关闭M$ Excel,运行脚本,等脚本运行结束。没有配置计时功能,但对于678例患者貌似5分钟不到的感觉。
代码说明
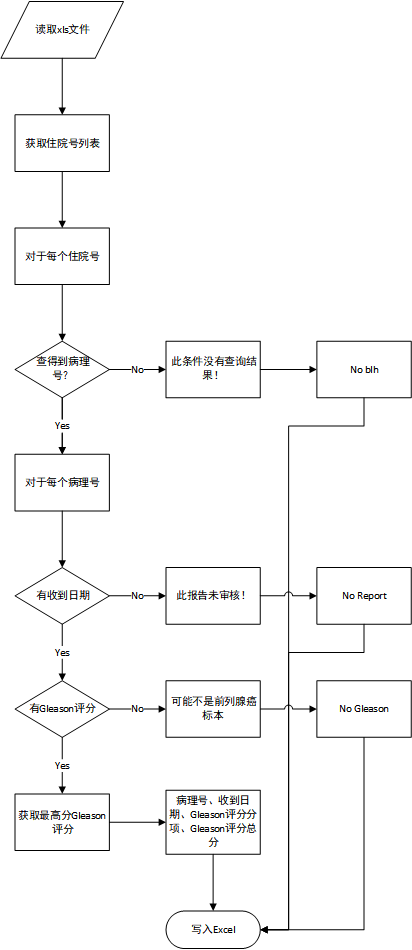
源代码Hospital_information_system_crawler_for_Gleason_Score.py已上传到GitHub。此处应该有个流程图。代码感觉不够优雅。
编程感想
从有了想法到代码完成,大概两天多时间吧。部署环境就花了至少4至6小时,包括下载和安全软件。医院的网速还算可以,就是win7系统安装新版的PyCharm专业版会提示缺少Java SDK,XP安装2017版 PyCharm社区版则一般显示安装包不全,XP一次安装Anaconda中途退出后再也安装不上。
真正写代码和调试的时间估计有10小时。PyCharm的各种辅助功能,跟多年前记事本学JavaScript相对,真是高科技了。第一次从服务器获得数据、第一次成功写入Excel时非常兴奋。写到凌晨效率和思考能力真是非常低,但又欲罢不能,想要快点完成,然而睡前折腾几个小时,真不如早上清醒时的效率。
代码的总体构思是参考《一个小爬虫爬取限定条件的国自然项目》和FOOFISH-PYTHON之禅的爬虫入门系列,后者提供了最基础的知识和思路,让人忍不住动手写一个爬虫的样子。朗珈病理查询系统 的网页结构实际上非常简单,就是三个框架,cookies随便用,没有反爬虫机制,从晚上到第二天上午编程的过程中,我请求了无数次,貌似都没什么警报之类的。
由于没用梯子不能上Google,遇到问题是通过Bing和搜狗解决,搜索结果质量较差,影响效率。在正则表达式的构建和Excel的读写上纠结最多时间。基本没有数据结构和数据库知识,所以感觉代码还是比较乱。使用的是模块化编程的思路,但是在模块代码的几个文件之间手动copy来copy去,没用到import功能,效率不高。


