微信公众号的文章中不允许添加除了公众号文章之外的站外链接,只能通过“阅读原文”、二维码等曲折方式实现。有时文章中的链接一多,就懒得改了,直接让读者通过“阅读原文”去查看超链接。但这样读者的体验并不好:一是点阅读原文之后会有一个提示不安全的跳转界面,二是HTML网文贴到公众号编辑器之后,链接样式就消失了,不手动改就看不出哪里是有链接的。
于是想到可以借鉴科技文章的写作方式,在原引用链接处添加序号,在文末给出参考链接。
可以先markdown写作,写作时使用inline link,写作完成之后用Python脚本批换为参考文献的形式。
脚本功能
markdown有三种链接形式:
1、行内链接 inline link:
1 | This is [an example](http://example.com/ "Title") inline link. |
直接在原文字处插入链接,点击跳转。这是最直接的方式,微信公众号不支持,保存之后自动消失;可以直接把链接放到原文字旁边,但是不够优雅。
2、参考式链接 reference link:
1 | This is [an example][id] reference-style link. |
这是一种并没有什么用的链接方式。对于读者来说都是直接点击跳转,但写作起来非常蛋疼,就跟手动插参考文献一样,修改起来很不方便。Copy到微信公众号编辑器,Markdown Here转换之后,也是保存不了。
3、脚注 Footnote:
1 | You can create footnotes like this[^footnote]. |
非常像是参考文献的形式了,但在微信公众号编辑器中保存之后[^footnote]还是会显示源代码字样,不好看。
可以先用markdown写作,写作完成之后运行
1 | python convert_markdown_inline_link_to_reference_footnote.py xxx.md |
自动将markdown文件中inline link转换为reference link,而且文末参考链接的形式还可以轻松自定义,如改为
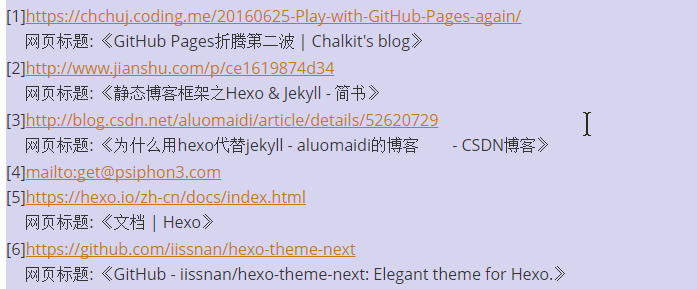
[序号]+链接+网页标题
的形式。
需要用到的工具
这是一个Python 3 脚本,在Microsoft Windows 10 (Home Insider Preview China 10.0.17025)、Anaconda 4.3.27、python 3.6.2、PyCharm 2017.2.4 环境调试完成。
需要用到的模块:
1 | import sys |
实现
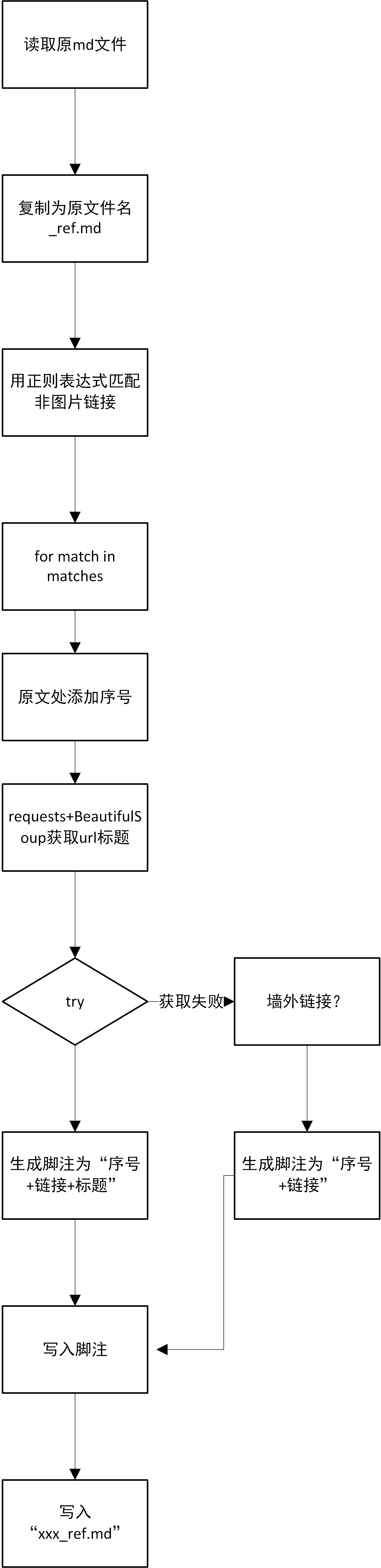
源代码`convert_markdown_inline_link_to_reference_footnote.py 已上传到GitHub。此处应该有个流程图。代码中都有详细的注释。
替换之后的效果如下图:

脚本配置
修改脚本中的footnote_mark 和 footnote_line 的替换格式,可以自定义生成的参考文献的格式。
如“序号+链接”、“序号+链接+标题”等
编程感想
这算是自己拼凑出来的一个Python脚本,拼凑来源仍然是https://github.com/JyHu/useful_scripthttps://github.com/hxzqlh/qiniu-markdown-pics 和 https://github.com/JyHu/useful_scripthttps://github.com/hxzqlh/qiniu-markdown-pics 两个脚本。
从一开始有了一个貌似可行的想法,就迫不及待地去把它实现了。一开始还想着是不是要用很复杂的方法去除match到的图片链接 ,没想到正规表达式里面一个非字符就轻松实现,print出一堆链接时很激动。
本代码涉及的主要知识点有文件的简单读写、正规表达式基础应用、request+BeautifulSoup获取网页标题、try异常处理。
完成这个脚本之后,发现貌似上述技能就是爬虫基础技能,于是又有了一个用爬虫批量获取内网HIS系统数据的想法,同样迫不及待地动手了。


