之前在泌尿轮科时见过一份没把“前列腺”一段删除的女性患者报告。现在想到可以用Python爬虫从放射影像系统中自动筛选出类似错误的报告。

开发工具
这是一个Python 3 脚本,在如下环境调试完成。
- Microsoft Windows 7 32位:医院办公室最高级的系统,XP安装新版Anaconda和PyCharm时有问题。部分代码先在我自己的win10 64电脑上完成。
- Anaconda3-5.0.1-Windows-x86.exe:墙内用户可从清华大学开源软件镜像站下载
- PyCharm-community-2016.3.3.exe:2017年的社区版安装包提示错误,只能安装旧一版。若在自己电脑上,可用专业版,edu邮箱用户福利。
- pycryptodome和pdfminer.six模块: Anaconda已内置其他所需模板,只需要离线安装这一个。pycryptodome是pdfminer.six的依赖环境,需要行安装。手动安装时使用whl格式最方便,不用解压,pip install 一下就好了。
- 通用电气医疗放射信息系统软件::一个网页版的查询系统
- IE + Fiddler: 这个查询系统只能用IE,Fiddler用来监控客户端与服务器的通讯情况,以及查找相关参数的位置。
- Hide Wizard
思路分析:
医院用的是通用电气医疗放射信息系统软件,先登录网页,搜索条件,再从搜索结果中点开PDF链接。因此,主要流程就是先模拟登录,爬取搜索结果,进行筛选,最后用解析PDF内容。
需要解决的问题有:
一、网页结构分析
通用电气医疗放射信息系统的放射影像查询首页是: /webreport/index.jsp
登录页面是/webreport/login.jsp
登录之后查询的页面是:/webreport/mainframe.jsp
跟朗珈病理查询系统类似,它由三个框架组成,查询框架中的onclick事件之后,请求结果会出现在检查列表框架,检查列表框架中点击再显示在历史检查框架或弹出新的报告或图像窗口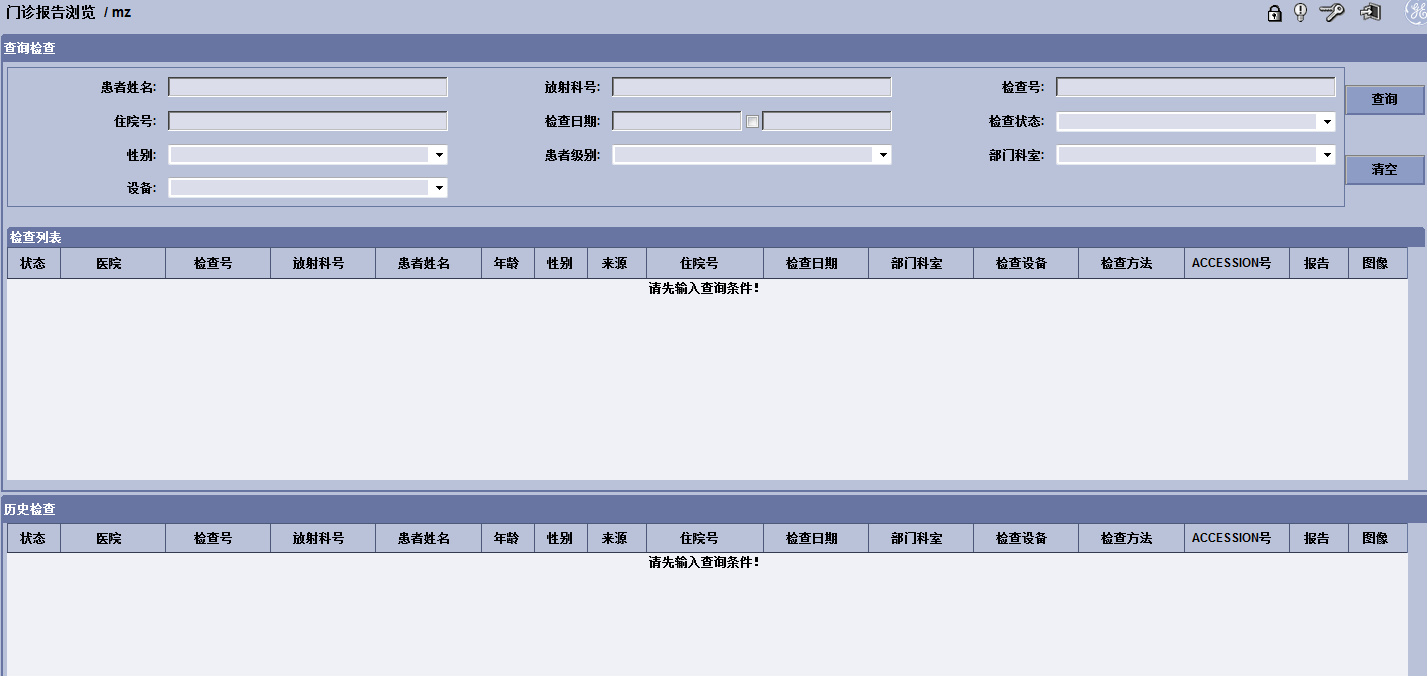
二、网页登录
网页登录是挡在所有网页爬虫面前的第一步,解决不了这一步,后面的内容都不用设计了。之前我爬的病理系统是兼容chrome的,在chrome使用F12查看网络信息就行了。而这次的GE系统只能在IE 10兼容性视图以下运行(chrome虽可登录,但看不到完整查询界面)。
IE 11 、IE 10的F12没有chrome的那么友好,而且不能切换IE的版本。折腾过程中发现QQ浏览器的F12也算是神器,它跟IE的开发者工具界面相同,但它可以切换各种IE版本及兼容性视图。
但真正算得上抓包神器的,应该是Fiddler。它可在win7下直接运行,不用配置,运行之后可以抓取所有程序的网络情况。
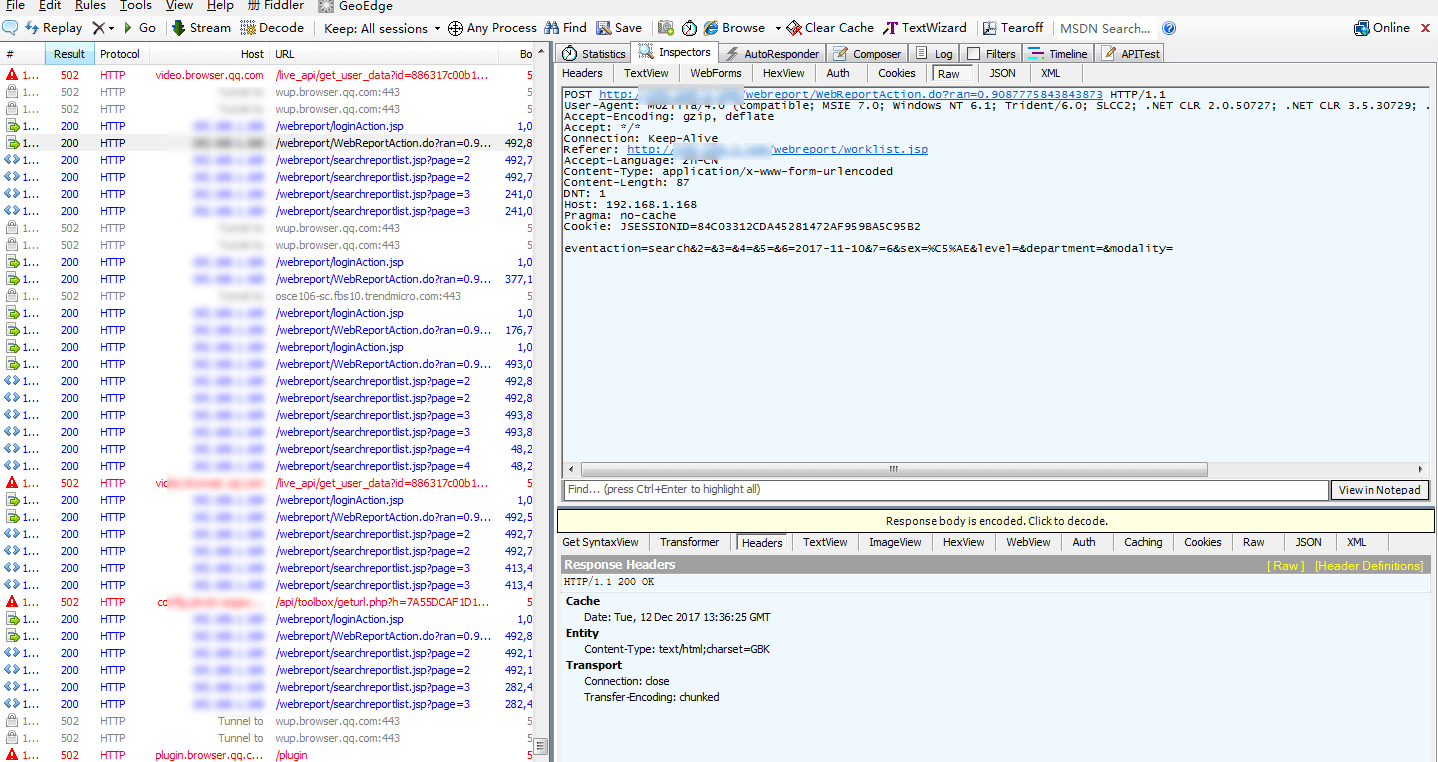
对于每一个抓到的网络请求和响应,提供Headers、TextView、WebView、Cookies、Raw、JSON、XML等各种视图和格式。WebView就是直接解析HTML,和浏览器一样,当你从python中模拟浏览器发送请求时,可以在Fiddler中非常直观地看到请求结果。
这个网页的登录非常简单,没有验证码,什么反爬虫的限制都没有。经过反复测试,确定了这个网站的登录模式:用一个随便的初始cookies从 /webreport/login.jsp 获取一个新的cookies,登录的信息就只保留在cookies中。
1 | def get_cookies(): |
唯一比较特别的是,这个系统隔段时间会自动退出,此时用旧的cookies就无法获取查询结果了,需要重新获取一个cookies。
由于一眼看不出这cookies的过期时间,于是,就简单粗暴地设定为每次发起新一天的查询就直接请求一个新的cookies,同时设定获取html之后再判断一下会话是否过期,过期就直接再请求一次:
1 | if re.search('top\.location\.replace',html)!=None: |
三、查询参数提交
折腾了好久,发现需要先将中文参数encode为GBK,才能正确地请求数据。
1 | params_data = { |
四、获取查询结果的html
通过Fiddle抓包发现,查询结果的首页是request_url =’/webreport/WebReportAction.do?ran=0.9087775843843873’ ,这个ran参数不知道是什么意义,但是貌似可以重复使用,有可能是记录客户端信息的吧
超过200条结果就会自动分页,分页的查询结果页面是 /webreport/searchreportlist.jsp
有意思的是,发送于一个POST请求之后,查询的信息储存于cookies中,请求第2页之后的信息,只需要用POST时用的cookies去GET就行了
1 | #从首页读取总页数,若有多页就继续请求分页数据并进行合并 |
五、从html中获取查询数据,并进行数据清洗
因为想从查询结果中筛选出CT和MR,并下载pdf进行分析,所以html中感兴趣的数据就是检查项目、检查号(用于作为数据ID)以及pdf链接。
查询结果是一个html表格,pdf链接最有特点,直接用一个正则表达式就能匹配出来:
1 | pdflinks = re.compile(r'openReport\(\'(.*?\.pdf).*?(\d{2,}).*?\)',re.S).findall(html) |
难点在于检查项目和检查号字段,它们的\<TD>标签内容和属性都没有特别之处,没办法直接建正则表达式,BeatutifulSoup也是用不上,搜索发现from lxml import etree模块也能匹配出来,但结果的处理仍然不够方便。
最后搜索parse html table发现pandas直接一个read_html方法就能直接把html里面的表格转换为DataFrame,非常震惊。DataFrame是科学计算包pandas的两种数据格式之一,就相当于一个放在内存中的Excel,基本上Excel能实现的功能,它都能做到。
1 | import pandas as pd |
于是也顺便把pdf链接转换为pandas的Series数据形式,并和DataFrame进行合并(利用了pandas的自动对齐功能)
1 | from pandas import Series |
DataFrame的合并也是非常方便,分页的DataFrame数据直接append就能垂直拼接
1 | sp500_table=sp500_table.append(get_page(page,cookies)) |
筛选出CT和MR检查直接用现成的srt.contains就行:
1 | sp500_table= sp500_table.loc[sp500_table[12].str.contains('CT|MR')] |
六、下载PDF
从查询结果的页面点击查询结果之后,触发JavaScript,弹出一个新的页面,显示pdf。然而,html源代码和新页面的链接中不能直接看出pdf的直达链接。接下来通用的方法应该是分析网页的JS,用selenium+PhatomJS模拟浏览器点击,去获取这个url。这也是一个比较蛋疼的过程。
但是,我突然想到电子病历中就有报告的直达链接,跑过去一个,发现是个FTP链接,而且码农们做接口时FTP的用户名和密码也不挡一下。用这个用户名和密码直接就登录了存储放射科数据的FTP,激动!
这FTP里面image一个文件夹,report一个文件夹。
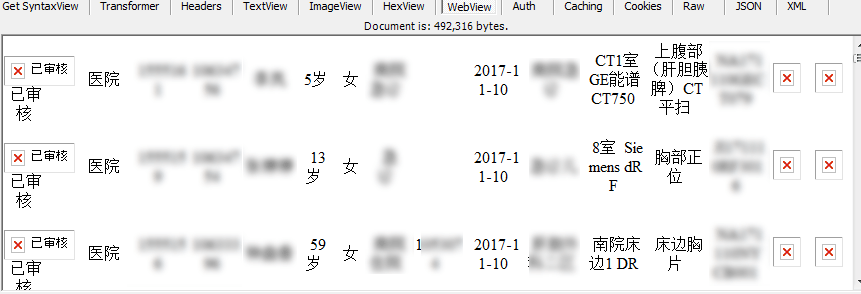
report里面每个月又分几个文件夹,每个子文件夹下面就是检查报告的pdf,pdf是以报告的Id来命名的。(每个患者的每顶检查都有一个放射号和检查号,每份报告有一个报告号,有时几个检查会合并在一份报告里面发)。
此时,也可以不用网页爬虫了,直接把这波pdf下载回去分析就行了。但要实现本项目的目的还是先分析html、筛选之后再下载pdf比较快,因为解析pdf速度比较慢。
从ftp下载pdf就非常简直了,直接上网去下载一个现成的脚本就行了,例如:http://www.cnblogs.com/hfclytze/p/ftplib.html ,模块也是Anaconda自带的。pdf的链接地址可以从html中获取。我是采取下一个文件之后分析处理完再下载另一个pdf的方法。
七、解析并处理pdf
从pdf中提取源数据实际上非常困难,而且这还是中文pdf,还要面对一堆编码的问题。幸好这个影像报告的PDF文件都制作精良,可以直接复制文字的。
但是解析pdf或从pdf中提取text的python3模块并不好找,python2最常用的是pdfminer。一开始我找了个移植的pdfminer.3k,测试了一个报告PDF,发现可以解析,于是非常兴奋,项目终于可以终于了,立即运行爬虫,下载分析。
问题来了,下载了几个月发现,每个月总有那么几篇报告解析错误,但手动打开报告是没问题的,还可以直接复制。每月几篇,那么一年的数据就有几十篇,手动打开查看就不能体现爬虫的优势了。
于是又分析测试了好几个pythonpdf包,包括tabula-py、pdfrw、textract、pdf2txt都不行。最后还是找到pdfminer的python3移植包pdfminer.six(大概是使用版本移植工具six做的吧),可以完善解析所有的PDF报告。
但这个pdfminer.six的文档写得非常差,就只有一个命令行的使用方法。在python中调用命令行工具去运行另一个py脚本,显然不够优雅,最后自己看了一个源代码,并从StackOverFlow中找到一个可行的py脚本(https://stackoverflow.com/a/46695574/9095642)。
1 | import pdfminer.settings |
在这里,英文搜索的优势得到充分体现,用中文搜索结果,有十几二十个页面全是某篇没有用的文章,大概是他一文多发之后又被其他各种网页抄去了。
八、分析过滤pdf
这一步非常简单,直接用从pdf的文字内容中搜索关键字,根据匹配结果决定保留pdf文件还是删除pdf
1 | def process_pdf(exam,localpath,get_count=0,pass_count=0,pdf_error=0): |
九、结果记录
由于这个爬虫项目运行起来比较久,所以需要动态记录运行的记录,确保意外退出时之后的工作记录得到保存。发现logging模块就能实现这个目的,但好的教程也不好找(http://www.cnblogs.com/yyds/p/6901864.html)。
1 | # http://www.csuldw.com/2016/11/05/2016-11-05-simulate-zhihu-login/ |
十、调试与运行
使用模块化编程,将上述功能组件写在不同的py文件里面,分别完成调试,最后包装成函数,互相import。
多用try语句。一开始没给整个大程序加一个try,设定了半夜再爬一年的数据的,结果搜索了4天的数据就退出了,浪费了晚上的时间。后来发现原因是2016年7月之前的外院片子会诊报告是无法察看的。
实际运行中发现,用4核i3 CPU的电脑大概1分多钟可以分析完约200份报告,就是说6个小时就能查完1年的数据;而双核奔腾CPU则需要双倍的时间。这里可以考虑用多线程或进程处理的方法,但需要进一步学习。
源码实现
源代码已上传到GitHub(点击阅读原文访问)。流程图就不画了。
关于源码的分析,可以参考代码中的注解,如有不理解的地方,可在评论中提出。
运行结果
不能公开。但是可以上交给国家。
More
其实都提取到纯文字了,下一步可以把抓取到的数据保存到一个数据库中,方便查询。然而,如果不能实际某个目的,那么这些数据只是垃圾,建立数据库没有意义。


